Introduction:
Agriculture is the backbone of food security and rural economies, yet plant diseases—caused by fungi, bacteria, viruses, insect pests, and nutrient imbalances—regularly reduce crop yields and degrade harvest quality. Tomato (Solanum lycopersicum) is a globally important vegetable crop that is particularly susceptible to a wide spectrum of foliar conditions (e.g., early/late blight, bacterial spots, viruses, nutrient deficiencies). Rapid, accurate identification of these conditions at scale is essential for timely management decisions, but conventional diagnosis relies on expert scouting and laboratory assays that are slow, costly, and often inaccessible to smallholder farmers. This gap motivates automated, image-based diagnostic tools that are both accurate and practical for on-field use.
Deep learning (DL) — especially Convolutional Neural Networks (CNNs) and, more recently, Vision Transformers (ViTs) — has proven highly effective for leaf-disease classification on curated datasets (for example, PlantVillage). However, three recurring obstacles limit practical adoption: (1) cross-domain generalization — models trained on controlled, single-domain images (uniform backgrounds, standardized lighting) underperform on field images that contain cluttered backgrounds, variable illumination, and occlusion; (2) severe class imbalance — many datasets contain abundant samples of a few common diseases while rare but important conditions have very few examples, biasing training; and (3) deployment constraints — state-of-the-art models are large and computationally expensive, making them unsuitable for typical smartphones and edge devices farmers use.
This project addresses those obstacles through an end-to-end pipeline designed for deployable cross-domain tomato leaf disease detection. The first pillar is dataset unification and augmentation: laboratory (PlantVillage) and field (TomatoVillage) collections are harmonized into a common 15-class taxonomy to expose models to a wider variety of visual conditions. Targeted augmentation (horizontal flips, rotation ±20°, brightness perturbation) and ADASYN (Adaptive Synthetic Sampling) balancing are applied during training to mitigate the domain gap and correct extreme imbalance by generating synthetic minority examples where they are most needed.
The second pillar is model design and optimization. Rather than relying on a single architecture, the pipeline uses ensemble learning (soft-voting across complementary backbones such as DenseNet-121, ResNet-101, DenseNet-201, EfficientNet-B4) to aggregate diverse feature representations and raise accuracy and robustness across domains. To make this high accuracy viable on constrained devices, the third pillar—model compression—employs knowledge distillation: the ensemble (teacher) guides a compact ShuffleNetV2 student so the student learns the teacher’s richer class relationships while retaining a much smaller parameter footprint. Post-training quantization (INT8) further reduces model size and computational cost to suit mobile deployment.
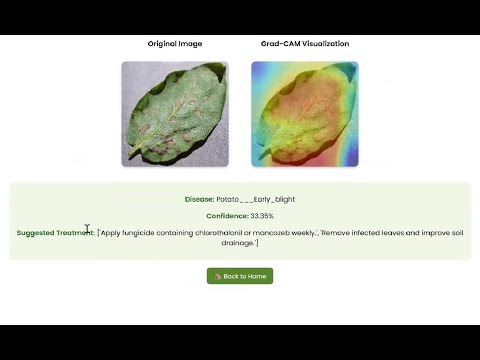
Explainability and trust are integral to adoption in agriculture, so the pipeline integrates explainable AI (XAI) methods: Grad-CAM++ visualizes spatial attention (which leaf regions the model uses), and LIME analyzes local decision boundaries via superpixel perturbations. These outputs let agronomists and farmers verify that model decisions focus on biologically meaningful features (lesions, chlorosis, necrotic edges) instead of spurious background cues.
Finally, emphasis is placed on practical deployment: the compressed and explainable model is packaged within a multilingual mobile application (Flutter-based) to ensure wide accessibility. Evaluation uses class-balanced metrics (macro F1) alongside accuracy and ROC/AUC to properly measure performance on imbalanced, multi-class data and to quantify cross-domain robustness.
Technical terms (brief):
• Ensemble learning: combining multiple models’ outputs (soft voting) to improve generalization.
• Knowledge distillation: training a small “student” model using soft targets from a larger “teacher” (or ensemble).
• Quantization (INT8): representing weights/activations with 8-bit integers to reduce memory and speed up inference.
• ADASYN: an adaptive oversampling technique that synthesizes minority samples based on local density.
• Grad-CAM++ / LIME: model-agnostic/local explanation methods for visualizing important pixels or superpixels.
In sum, the project integrates data-level, model-level, and deployment-level strategies to produce a scalable, accurate, and interpretable tomato leaf disease detection system suitable for real agricultural use.
Rationale Plant leaf diseases remain one of the leading causes of agricultural yield loss worldwide, threatening both food security and farmer income. Tomato, a crop of immense global and economic importance, is highly susceptible to a range of foliar diseases caused by fungal, bacterial, viral, and nutrient-related factors. Early identification and proper management of these diseases are critical to preventing crop failure. However, traditional approaches such as expert-based diagnosis and laboratory testing are time-consuming, expensive, and often inaccessible to farmers in rural and resource-limited settings. This situation creates a strong need for automated and accessible solutions that can accurately identify diseases and support farmers in making timely decisions for crop protection.
Although deep learning has emerged as a powerful tool for plant disease detection, existing approaches face several critical challenges when applied outside controlled laboratory conditions. Models trained on standardized datasets often fail to generalize to field images due to variations in lighting, background, and leaf positioning. Additionally, severe class imbalance in disease datasets—where a few diseases dominate while rare but harmful ones have very limited samples—reduces model reliability and accuracy. Furthermore, advanced deep learning architectures are computationally heavy, restricting their deployment on smartphones and edge devices commonly available to farmers.
To address these gaps, there is a strong justification for developing a deployable deep learning framework that integrates multiple optimization strategies. By combining ensemble learning for higher accuracy, knowledge distillation for transferring knowledge into compact models, and quantization for reducing model size and computation, this project aims to deliver a lightweight, scalable, and efficient solution. The inclusion of explainable AI (XAI) techniques ensures that the model’s decisions are transparent and interpretable, fostering user trust. This integrated approach will help bridge the gap between research and agricultural practice, enabling farmers to detect diseases efficiently, reduce losses, and contribute to sustainable food production.
Objectives :
1. To develop a cross-domain benchmark dataset for tomato leaf disease detection by combining laboratory and field images, while addressing class imbalance through data augmentation and adaptive synthetic sampling (ADASYN).
2. To design and implement a robust ensemble learning framework by integrating multiple deep learning architectures (e.g., DenseNet, ResNet, EfficientNet) to achieve high classification accuracy across diverse agricultural conditions.
3.To optimize the model for deployability by applying knowledge distillation and quantization techniques, thereby producing a lightweight, efficient, and scalable model suitable for mobile and edge devices.
4. To enhance trust and usability through explainable AI (XAI) methods such as Grad-CAM++ and LIME, ensuring transparency of predictions and supporting practical adoption in precision agriculture.
Block Diagram
• Demo Video
• Complete project
• Full project report
• Source code
• Complete project support by online
• Life time access
• Execution Guidelines
• Immediate (Download)
Software Requirements:
1. Front-end:
• HTML
• CSS
• Bootstrap
• JavaScript
2. Back-end:
• Python
• Flask
• Datasets
• Open Cv
•MLP
•NMT
3. Database:
•SQL lite
•DB browser
4. Vs Code
Hardware Requirements:
1. PC or Laptop
2. 500GB HDD with 4 GB above RAM
3. Keyboard and mouse
4. Basic Graphis card
1. Immediate Download Online