ABSTRACT
Gun violence and public safety threats have become major concerns in modern society, and the ability to automatically detect gunshot sounds can play a vital role in ensuring quick emergency response and crime prevention. Manual monitoring of surveillance audio streams is highly inefficient and error-prone due to the vast volume of sound data and human limitations in continuous listening. To address this issue, this project proposes an intelligent Gunshot Sound Classification System that automatically identifies gunshot sounds from ambient environmental audio using deep learning techniques. The system is designed to classify an input sound into two primary categories — Gunshot and Normal Sound — through the use of a Convolutional Neural Network (CNN) trained on Mel-spectrogram representations of short audio clips. Each sound file is preprocessed using the Librosa library to extract Mel-frequency spectrogram features, which effectively capture the time-frequency characteristics of the sound in a two-dimensional format suitable for CNN learning.
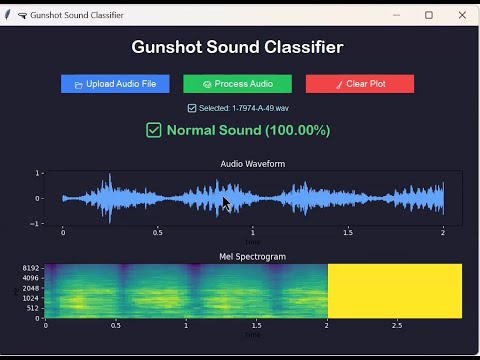
The model is trained on a custom dataset containing both gunshot and normal sound samples, standardized to a sampling rate of 22,050 Hz and fixed to a duration of two seconds per sample. A well-structured CNN architecture with convolutional, pooling, and dense layers is used to learn discriminative features that differentiate between sharp impulsive gunshot patterns and smoother background noises. The network is compiled with the Adam optimizer and categorical cross-entropy loss function to achieve high accuracy and stable convergence. Experimental results demonstrate a strong performance, with a validation accuracy exceeding 90%, confirming the model’s ability to generalize effectively to unseen sounds. To enhance usability, a Graphical User Interface (GUI) is developed using Tkinter, which allows users to upload an audio file, visualize its waveform and Mel-spectrogram, and instantly obtain prediction results along with confidence scores. The GUI provides visual feedback through colored text indicators and dynamic plotting using Matplotlib.
Beyond detection, the system incorporates an alert mechanism for real-time response. When a gunshot is detected, an alarm sound is automatically played through the speakers, and an SMS notification is sent to a predefined mobile number using the Twilio API. This ensures that authorities or security personnel are promptly informed of possible threats, minimizing reaction time during critical incidents. The entire framework runs efficiently on standard hardware and can be extended for real-time deployment using microphone input streams or surveillance networks. By combining the analytical power of deep learning with practical human-machine interaction, this project demonstrates a scalable solution to audio-based threat detection. Overall, the proposed system represents a significant step toward intelligent public safety monitoring, merging AI-driven sound recognition, real-time alerting, and user-friendly visualization into a single cohesive application capable of assisting in early threat identification and response automation.
INTRODUCTION
Sound plays a critical role in our daily lives, carrying valuable information about the surrounding environment. In recent years, the ability to automatically interpret and classify environmental sounds has become an essential component of modern intelligent systems, particularly in the fields of surveillance, security, and public safety. Among various acoustic events, the detection of gunshot sounds is one of the most crucial applications because of its direct connection to life-threatening situations
Gunshot sounds are typically characterized by short, high-energy acoustic impulses that differ significantly from other environmental noises such as traffic, human voices, or animal sounds. However, the variability in recording devices, background noise levels, and distances from the sound source make manual detection or traditional rule-based methods ineffective. Therefore, the use of deep learning techniques, specifically Convolutional Neural Networks (CNNs), provides a more data-driven and feature-adaptive approach to sound classification. CNNs are known for their capability to automatically learn spatial hierarchies of features from images or spectrograms, making them ideal for processing Mel-spectrograms — a time-frequency representation of sound. In this project, gunshot and normal sounds are converted into Mel-spectrograms using the Librosa library, which extracts key frequency patterns representing how sound energy is distributed across time. These spectrograms are then used as inputs to a CNN model that learns to distinguish gunshot events from normal ambient sounds.
The motivation behind this project stems from the growing need for automated systems capable of recognizing and responding to critical acoustic events without human intervention. Real-time gunshot detection can significantly reduce response times in emergency scenarios, helping to save lives and prevent further damage. Traditional sound detection techniques, which rely on handcrafted features like zero-crossing rate or spectral centroid, often fail to generalize across different environments.
The GUI, designed using Tkinter, serves as the user-facing component of the system. It provides clear visualizations of both the waveform and the Mel-spectrogram of the uploaded audio file using Matplotlib, allowing users to visually inspect sound characteristics. Once the user selects a file, the system preprocesses it to ensure a consistent sampling rate and duration, then generates the Mel-spectrogram feature map.
The model itself is constructed using TensorFlow Keras, featuring multiple convolutional and pooling layers that extract hierarchical sound patterns, followed by dense layers that perform final classification. It is trained on a custom dataset containing balanced samples of gunshot and non-gunshot audio clips.
One of the distinctive aspects of this project is its end-to-end integration of deep learning, visualization, and communication technologies into a single cohesive system. The CNN ensures reliable sound classification, the GUI enhances accessibility for non-technical users, and the alert mechanism bridges the gap between detection and response.

• Demo Video
• Complete project
• Full project report
• Source code
• Complete project support by online
• Lifetime access
• Execution Guidelines
• Immediate (Download)
Software Requirements
The software requirements for the Maternal Health Monitoring System include a combination of development, execution, and machine learning tools essential for building a web-based predictive healthcare platform. The backend is developed using Python, supported by libraries such as Flask for web routing, scikit-learn for machine learning, pandas and NumPy for data processing, and joblib for model serialization. The system also uses Tesseract OCR along with the PIL and PyMuPDF libraries for medical report text extraction from images and PDFs. The frontend interface is designed using HTML, CSS, and JavaScript to ensure responsive and interactive user experiences. A lightweight SQLite database handles user authentication and data storage. The entire project runs seamlessly on Windows, macOS, or Linux platforms with Python 3.8+ installed. Additional tools such as a modern web browser (Chrome/Firefox) and optional IDEs like VS Code or PyCharm are recommended for development.
HARDWARE REQUIREMENTS
The hardware requirements for the system are minimal, as the project is designed to run efficiently on standard computing resources. A basic system with a dual-core processor (Intel i3 or equivalent), 4 GB RAM, and at least 500 MB of free disk space is sufficient for development and execution. For smoother machine learning operations and faster OCR processing, a system with 8 GB RAM is recommended. A stable internet connection is required for hosting, accessing the web interface, or uploading medical reports. The application can run on any desktop or laptop device; no specialized hardware components are needed unless integrating future extensions such as wearable sensors or mobile device data acquisition. The simplicity of hardware requirements makes the system easily deployable for general users and healthcare environments.
1. Immediate Download Online