ABSTRACT
The accurate assessment of haemodynamic pressure is a critical requirement in emergency medicine and critical care environments. Conventional blood pressure monitoring techniques are often invasive, contact-based, and resource-intensive, which limits their suitability for continuous or rapid screening. In response to these limitations, this project presents a deep learning-based, non-contact medical image classification system for identifying haemodynamic pressure states.
The proposed system classifies diagnostic images into three clinically relevant categories: Low but present pressure, Moderately low pressure indicating hypovolemia or hypotension, and No detectable signal. An EfficientNet-B7 convolutional neural network is employed as the backbone architecture due to its superior parameter efficiency and strong performance on high-resolution images. To further enhance feature representation, a Convolutional Block Attention Module (CBAM) is integrated into the network, enabling adaptive emphasis on important spatial regions and feature channels.
The dataset undergoes comprehensive preprocessing, including resizing, normalization, and extensive data augmentation techniques such as rotation, zooming, flipping, and shifting to improve generalization and reduce overfitting. The training process is conducted in two stages, consisting of initial head training with frozen base layers followed by fine-tuning of the upper layers using a reduced learning rate.
The final trained model demonstrates reliable classification performance and robustness across varied image conditions. For real-world usability, a lightweight graphical user interface is developed using Tkinter, allowing users to select images and obtain predictions without technical expertise. This system offers a practical, non-invasive, and efficient solution for real-time haemodynamic pressure assessment and clinical decision support.
INTRODUCTION
This project presents an end to end deep learning pipeline that classifies diagnostic images into three haemodynamic pressure states—“Low but present pressure,” “Moderately low pressure (hypovolaemia / hypotension range),” and “No detectable signal.” The codebase is organised in two logical blocks: (1) model training and fine tuning, and (2) stand alone inference with a lightweight graphical interface.
1. Problem Context and Motivation
Accurate, rapid assessment of circulatory status is critical in emergency and critical care settings. Traditional invasive measurements are precise but resource intensive and carry procedural risks. Leveraging computer vision on routinely acquired images (e.g., perfusion maps, thermograms, or visualised plethysmographic signals) offers a non invasive alternative. The objective of this work is therefore to learn discriminative visual features that reliably map an input image to one of three clinically meaningful pressure categories, enabling point of care screening and continuous monitoring.
2. Dataset and Pre processing
Images are organised in a class balanced directory structure under ./dataset/, automatically discovered with glob and load_files. Each file is resized to 600 × 600 px (training) or 224 × 224 px (baseline CNN), converted to floating point tensors, and normalised to [0, 1]. A comprehensive augmentation scheme—random rotations, shifts, zooms, shears, and flips—multiplies the training set five fold, improving generalisation to unseen acquisition angles, lighting conditions, and patient variability.
3. Network Architecture
The backbone is EfficientNet B7, chosen for its strong parameter efficiency on high resolution inputs. All pretrained weights are initially frozen to preserve generic visual filters. A Convolutional Block Attention Module (CBAM) is then appended to adaptively recalibrate channel wise and spatial feature responses, directing the network’s focus toward perfusion relevant structures while suppressing background noise. Global average pooling, a 256 unit ReLU activated fully connected layer with 50 % dropout, and a softmax classifier complete the architecture.
4. Optimisation Strategy
Training proceeds in two phases:
o Head training. With the backbone frozen, the classifier head is trained for 30 epochs using RMSprop (η = 4 × 10⁻⁴) and early stopping.
o Fine tuning. The final 30 layers of EfficientNet are unfrozen, and the network is refined for a further 10 epochs at a reduced learning rate (1 × 10⁻⁵). Callbacks for learning rate reduction, best model checkpointing, and patience based early stopping safeguard against overfitting.
Training and validation curves are plotted for transparency, and the best weights are serialised as poenb7_cbam_finetuned.h5.
5. Inference and User Interface
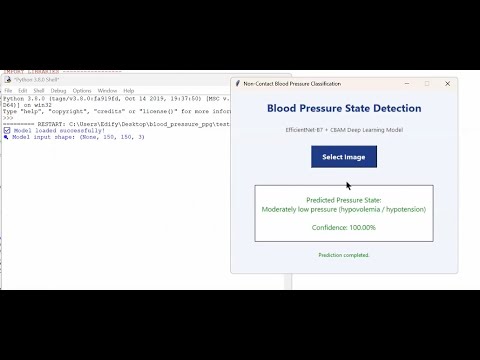
A self contained Tkinter GUI (select_image()):
o launches a file chooser dialog,
o preprocesses the selected image identically to the training pipeline,
o loads the frozen model (poenb7_cbam_model.h5) in inference only mode, and
o displays the predicted pressure class in a pop up message.
This design allows clinicians or researchers to obtain real time predictions without command line interaction or re training.
6. Deliverables and Reproducibility
o Source code with clear functional segmentation (data loading, augmentation, CBAM definition, training loop, GUI).
o Trained model weights for immediate deployment.
o Plots of accuracy and loss trajectories to document convergence behaviour.
o Modular functions (path_to_tensor, load_and_prepare_image, predict_image) that facilitate extension to alternative backbones, additional attention mechanisms, or larger datasets.
Block Diagram
SYSTEM REQUIREMENTS
A. Hardware Requirements
1. A personal computer or laptop with an Intel Core i3 processor or higher to support model training and real-time inference.
2. Minimum 8 GB of RAM to ensure smooth execution of deep learning models and NLP pipelines.
3. At least 20 GB of free disk space for storing datasets, trained models, libraries, and application files.
4. A stable internet connection for downloading pretrained language models and required Python libraries.
5. Standard keyboard and mouse for user interaction with the web-based chatbot interface.
6. Optional GPU support for faster model training and improved performance during experimentation.
7. Display unit with a minimum resolution of 1366×768 pixels for proper visualization of the web interface.
B. Software Requirements
1. Operating System: Windows 10 / Linux / macOS for running the development and deployment environment.
2. Programming Language: Python version 3.8 or above for implementing the chatbot logic and web application.
3. Development Environment: Any Python-compatible IDE such as VS Code, PyCharm, or Jupyter Notebook.
4. NLP Libraries: NLTK for tokenization, lemmatization, and text preprocessing.
5. Deep Learning Framework: TensorFlow and Keras for building, training, and deploying the intent classification model.
6. Language Detection Library: spaCy with language detection extensions for automatic language identification.
7. Translation Framework: Ollama Local model