ABSTRACT
Human speech conveys not only linguistic information but also emotional states, which play a vital role in effective human communication. Emotions expressed through speech influence decision-making, behavior, and interpersonal interactions. Automatic detection of emotions from voice has therefore become an important research area in fields such as human–computer interaction, mental health monitoring, customer support systems, smart assistants, and security applications. Enabling machines to recognize human emotions allows systems to respond more intelligently and empathetically.
Traditional speech emotion recognition systems relied heavily on handcrafted audio features such as Mel-Frequency Cepstral Coefficients (MFCC), pitch, energy, and spectral features. While these approaches showed moderate success, their performance was limited in real-world scenarios due to background noise, speaker variability, and lack of generalization. Moreover, many existing systems require continuous internet connectivity and are not suitable for offline or real-time deployment.
Recent advancements in deep learning and self-supervised learning have significantly improved speech processing capabilities. Models such as HuBERT (Hidden-Unit BERT) learn powerful speech representations directly from raw audio without requiring labeled data during pretraining. HuBERT captures high-level contextual and emotional information from speech, making it highly effective for emotion classification tasks.
This project proposes a Voice Emotion Detection System using a pre-trained HuBERT deep learning model. The system is designed to work completely offline, ensuring privacy, reliability, and usability in environments with limited or no internet access. It supports two modes of operation: a web-based emotion detection system implemented using the Flask framework, and a real-time desktop application developed using a graphical user interface.
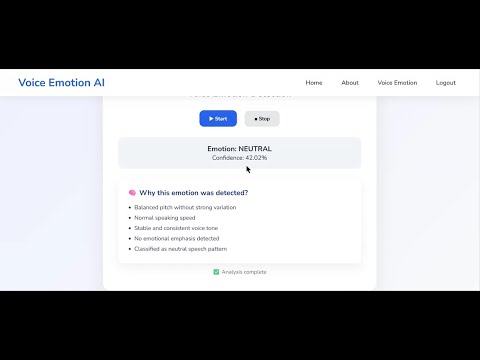
In the web-based system, users securely log in and provide voice input through the browser. The recorded audio is converted into a standard format, preprocessed, and passed through the HuBERT model for emotion classification. In the desktop application, real-time audio is captured directly from the microphone, processed continuously, and analyzed to detect emotions dynamically. Both systems output the detected emotion along with a confidence score.
The system classifies emotions into categories such as confident, neutral, angry, sad, fear, disgust, and surprise. Experimental results show that the proposed approach achieves high accuracy and stable performance under real-world conditions. By combining deep learning, offline processing, and real-time analysis, the proposed system demonstrates strong potential for deployment in practical applications such as mental health assessment, customer behavior analysis, and intelligent human–machine interaction.
INTRODUCTION
Human communication is not limited to spoken words alone; it also involves emotions, tone, pitch, and expressions that convey deeper meaning. Among various modes of communication, speech is one of the most natural and powerful ways humans express emotions such as happiness, anger, sadness, fear, confidence, and surprise. These emotional cues play a critical role in interpersonal communication, decision-making, and social interaction. Understanding emotions from speech has therefore become an important area of research in the field of Speech Emotion Recognition (SER).
With the rapid growth of artificial intelligence and machine learning technologies, there is an increasing demand for systems that can interact with humans in a more natural and intelligent manner. Emotion-aware systems can significantly enhance human–computer interaction (HCI) by allowing machines to respond not only to what is said but also to how it is said. Applications of speech emotion recognition include mental health assessment, customer service analytics, call center monitoring, intelligent virtual assistants, smart healthcare systems, education platforms, and security applications.
Traditional speech emotion recognition systems primarily relied on handcrafted acoustic features such as Mel-Frequency Cepstral Coefficients (MFCCs), pitch, energy, zero-crossing rate, and formant frequencies. These features were extracted manually and fed into classical machine learning classifiers such as Support Vector Machines (SVM), k-Nearest Neighbors (KNN), and Random Forest algorithms. Although these systems achieved reasonable accuracy in controlled environments, they suffered from several limitations. The performance of handcrafted features was highly sensitive to background noise, speaker variations, recording devices, and environmental conditions. Additionally, feature engineering required domain expertise and was not scalable for real-world applications.
Another major limitation of many existing systems is their dependence on internet connectivity. Cloud-based speech processing services require continuous network access, raising concerns related to latency, reliability, data privacy, and security. In applications such as healthcare monitoring or private user interaction, transmitting voice data to external servers may not be acceptable. Furthermore, many traditional systems lack real-time processing capabilities, making them unsuitable for applications that require immediate emotional feedback.
Recent advancements in deep learning and self-supervised learning have transformed the field of speech processing. Deep neural networks have shown the ability to automatically learn complex and high-level representations from raw data without relying on handcrafted features. In particular, self-supervised speech models such as wav2vec 2.0 and HuBERT (Hidden-Unit BERT) have demonstrated remarkable performance in speech recognition, speaker identification, and emotion classification tasks.
HuBERT is a self-supervised learning model that learns speech representations by predicting masked hidden units derived from acoustic clustering. Unlike traditional supervised models, HuBERT does not require large amounts of labeled data during pretraining. This makes it highly effective for learning rich contextual and emotional information from raw audio signals. As a result, HuBERT-based models provide improved robustness, generalization, and accuracy, even in noisy and real-world conditions.
This project focuses on the development of a Voice Emotion Detection System using a pre-trained HuBERT deep learning model. The proposed system is designed to operate completely offline, ensuring user privacy, reliability, and independence from network availability. The system captures voice input, preprocesses the audio to a standardized format, extracts deep speech features using HuBERT, and classifies emotions using a neural network-based classification head. The final output includes both the detected emotion and a confidence score indicating prediction reliability.
To enhance usability and real-world applicability, the system supports two different platforms. The first is a web-based application developed using the Flask framework, which allows users to securely log in and record voice input through a browser interface. The second is a real-time desktop application implemented using a graphical user interface, which continuously captures audio from the microphone and displays emotion predictions dynamically. This dual-platform approach ensures flexibility and allows the system to be used in multiple deployment scenarios.
The proposed system is capable of recognizing multiple emotional states, including confident, neutral, angry, sad, fear, disgust, and surprise. Audio preprocessing techniques such as resampling, mono conversion, and silence handling are employed to improve model performance. The use of HuBERT eliminates the need for manual feature engineering and enables the system to adapt effectively to different speakers and recording environments.
In addition to emotion recognition, the project emphasizes real-time performance and system stability. Efficient audio processing pipelines and optimized deep learning inference ensure minimal latency during prediction. Proper exception handling and resource management are implemented to maintain continuous operation without system crashes or data loss.
Overall, this project aims to bridge the gap between academic research and real-world deployment of speech emotion recognition systems. By combining deep learning, offline processing, and real-time user interaction, the proposed Voice Emotion Detection System provides a practical, scalable, and efficient solution for emotion-aware intelligent systems. The project demonstrates how advanced speech models like HuBERT can be effectively integrated into real-world applications, opening new possibilities for emotionally intelligent human–machine interaction.
OBJECTIVES
1. To design and develop an offline voice emotion detection system that can identify human emotional states from speech signals without requiring internet connectivity.
2. To implement a self-supervised deep learning approach using the HuBERT model for extracting rich and meaningful speech representations capable of capturing emotional and semantic information.
3. To eliminate dependence on handcrafted audio features such as MFCCs by enabling end-to-end emotion recognition directly from raw audio inputs.
4. To achieve real-time emotion recognition performance, ensuring low latency and immediate emotion classification for interactive applications.
5. To classify multiple emotional states such as confident, neutral, angry, sad, fear, disgust, and surprise from spoken voice samples.
6. To ensure robustness against real-world challenges including background noise, speaker variability, and different speaking styles.
7. To develop a cross-platform architecture that supports both web-based emotion detection using Flask and desktop-based real-time emotion detection through a graphical user interface.
8. To maintain user privacy and data security by processing all voice data locally without transmitting audio to cloud servers.
9. To design a modular and scalable system architecture that allows easy integration of future enhancements such as multilingual support and multimodal emotion analysis.
10. To evaluate the performance of the proposed system in terms of accuracy, real-time responsiveness, and practical usability in real-world environments.
Block Diagram
• Demo Video
• Complete project
• Full project report
• Source code
• Complete project support by online
• Lifetime access
• Execution Guidelines
• Immediate (Download)
SYSTEM REQUIREMENTS
The successful implementation of the Voice Emotion Detection System requires a well-defined combination of hardware and software resources to ensure accurate emotion recognition, real-time performance, and offline functionality. Since the proposed system integrates deep learning, audio processing, and user interaction interfaces, careful consideration of system requirements is essential. These requirements ensure smooth execution of the HuBERT-based emotion recognition model, efficient handling of audio data, and reliable operation across different platforms such as web and desktop environments.
From a hardware perspective, the system requires a computing device capable of handling deep learning inference and real-time audio processing. A standard desktop computer or laptop with a modern multi-core processor is sufficient to execute the application efficiently. The processor plays a critical role in handling audio preprocessing, model inference, and user interface responsiveness. While the system can operate on a CPU-only environment, a processor with higher clock speed and multiple cores significantly improves performance and reduces latency during real-time emotion detection. The proposed system is designed to be hardware-efficient and does not mandate the use of high-end GPUs, making it accessible for deployment on commonly available systems.
Memory availability is another crucial requirement for the system. Since the HuBERT model is a deep neural network with millions of parameters, sufficient RAM is required to load the model and perform inference smoothly. A minimum of 8 GB RAM is recommended to avoid performance bottlenecks, especially when running the system alongside other background applications. Adequate memory ensures that audio buffers, model weights, and intermediate tensors are handled efficiently without causing system slowdowns or crashes. Systems with higher memory capacity can achieve better stability during prolonged real-time usage.
Storage requirements for the system are moderate but important. The system requires disk space to store the operating system, Python environment, required libraries, pre-trained HuBERT model files, and application source code. The HuBERT model files occupy a significant portion of storage compared to traditional machine learning models. Additionally, temporary audio files may be created during processing in the web-based implementation. Therefore, sufficient free disk space is necessary to ensure smooth file handling and cleanup operations. Solid State Drives (SSDs) are preferred over traditional hard drives due to faster read and write speeds, which improve application responsiveness.
An essential hardware component of the system is an audio input device. A functional microphone is required to capture human speech accurately. For desktop usage, an inbuilt laptop microphone or an external USB microphone can be used. In the web-based implementation, the browser accesses the system microphone for voice recording. The quality of the microphone directly affects the accuracy of emotion detection, as clearer audio signals allow the deep learning model to capture emotional nuances more effectively. While high-end microphones are not mandatory, a noise-free recording environment significantly enhances system performance.
On the software side, the system requires a stable operating system capable of supporting Python-based development and execution. The application is compatible with widely used operating systems such as Windows, Linux, and macOS. For embedded or lightweight deployments, Linux-based operating systems are preferred due to their stability and efficient resource management. The operating system must support audio drivers, Python runtime, and necessary deep learning libraries to ensure smooth operation.
Python serves as the core programming language for the entire system due to its extensive support for machine learning, audio processing, and web development. A compatible Python version must be installed to ensure library compatibility and system stability. Python provides flexibility, rapid development capability, and seamless integration with deep learning frameworks. Virtual environments are recommended to manage dependencies effectively and avoid conflicts between different library versions.