ABSTRACT:
Deepfake technology, characterized by its ability to generate highly realistic fake videos by swapping faces, has become a significant societal concern due to its potential for misuse. The emergence of multimodal Deepfakes, incorporating both visual and auditory manipulations, presents a formidable challenge for traditional detection methods. This paper proposes DDformer, a novel approach aimed at addressing the challenges of heterogeneity and complementary fusion of data in multimodal Deepfake detection. DDformer introduces two fusion methods, Multimodal Fusion Transformer (MFT) and Shared Weight Attention Fusion (SWAF), to effectively integrate shallow and deep features. Furthermore, a specialized classifier is developed to accurately identify various types of Deepfake videos by leveraging fused multimodal features. Extensive experiments conducted on the FakeAVCeleb dataset demonstrate that DDformer achieves state-of-the-art performance, offering a promising solution for reliable and nuanced multimodal Deepfake detection systems.
INTRODUCTION:
The rapid evolution of artificial intelligence has ushered in a plethora of generative models that offer unprecedented convenience in various aspects of our lives. However, this progress has also given rise to techniques employing these models to fabricate synthetic faces, most notably exemplified by Deepfake technology. Unfortunately, the accessibility of Deepfake tools has led to widespread misuse, inundating the internet with a plethora of fabricated videos. These manipulated visuals, often combined with forged audio, permeate various domains including pornography, political discourse, financial scams, and more, engendering significant societal ramifications such as jeopardizing social stability, financial security, and personal privacy. Initially, Deepfake technology predominantly focused on manipulating facial features. However, with the integration of synthesized speech, the complexity of Deepfake synthesis has escalated, rendering the detection of multimodal Deepfakes an urgent imperative. These multimodal Deepfakes amalgamate visual and auditory information, rendering conventional visual-based detection methods inadequate. Consequently, state-of-the-art detection mechanisms rely on multimodal learning, leveraging the interrelationships between different modalities such as sound, text, and images to enhance detection accuracy.
Nevertheless, the field of multimodal learning for Deepfake detection faces two pivotal challenges: effectively managing the heterogeneity of multimodal data and leveraging the complementary nature of these modalities. Several approaches have been proposed to address these challenges. For instance, AVoiD-DF tackles heterogeneity by transforming auditory data into spectrograms, enabling fusion through bidirectional cross-attention blocks. However, existing methods often overlook temporal relationships within modalities and fail to effectively exploit multimodal homogeneity, leading to limited classification granularity. In this context, this paper proposes DDformer, a novel approach designed to address the challenges of heterogeneity and complementary fusion of data in multimodal Deepfake detection. DDformer introduces innovative fusion methods, namely Multimodal Fusion Transformer (MFT) and Shared Weight Attention Fusion (SWAF), to seamlessly integrate shallow and deep features. Additionally, a tailored classifier is devised to accurately identify various types of Deepfake videos by effectively leveraging fused multimodal features. Through extensive experimentation on the FakeAVCeleb dataset, DDformer demonstrates state-of-the-art performance, offering a promising solution for reliable and nuanced multimodal Deepfake detection systems.
PROBLEM STATEMENT:
The rapid proliferation of Deepfake technology, which combines visual and auditory manipulations to create highly realistic fake videos, poses a significant challenge to traditional detection methods. Existing approaches often struggle to effectively detect multimodal Deepfakes due to the heterogeneity of multimodal data and the difficulty in leveraging complementary features from different modalities. Consequently, there is a pressing need for innovative techniques that can accurately identify and classify various types of multimodal Deepfakes to mitigate the spread of misinformation and protect societal integrity.
OBJECTIVE:
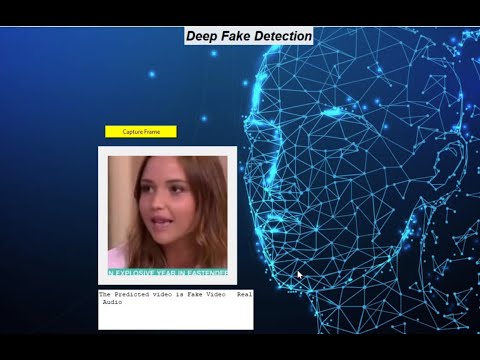
In real time, if the video and audio is real it will detect as real, and if video is real and audio is fake it should detect the audio is fake, and if the video is fake and audio is real it should detect as audio is fake, if both also it should detect as fake.
Block Diagram