ABSTRACT
This project presents a hybrid multimodal federated learning system designed to monitor and classify on-screen user activities by analyzing both visual and textual content. The system leverages a convolutional neural network (CNN) for image feature extraction and a long short-term memory (LSTM) network for sequential text analysis, integrating both modalities to enhance classification accuracy. The client-side component captures real-time screenshots, extracts embedded text using Tesseract OCR, preprocesses the data, and participates in model training through a federated learning framework. The server, built using Flask, coordinates encrypted model updates and disseminates the decrypted global models back to clients. A custom multimodal deep learning architecture, combining image and text features, is employed to categorize screen activity into predefined classes. This approach ensures scalable, secure, and privacy-conscious model training across distributed environments while enabling real-time screen activity recognition.
INTRODUCTION
In the modern era, the proliferation of digital devices and internet accessibility has significantly transformed the landscape of human-computer interaction. Screen-based applications ranging from social media, productivity tools, entertainment platforms, to educational software are central to both professional and personal domains. With this increased reliance on screen-based interfaces, there emerges a compelling need for systems capable of monitoring, understanding, and classifying user activities in real-time. Such systems have numerous practical applications, including parental control, workplace productivity monitoring, e-learning engagement assessment, digital wellbeing interventions, and cyber security.
While traditional screen activity monitoring solutions primarily focus on either image-based recognition or textual analysis, they often fail to leverage the full spectrum of multimodal information that is present on a typical display. For instance, a screenshot might contain a blend of graphical elements and embedded text that, when analyzed together, provide a far richer and more contextual understanding of the screen's content. Recognizing this, the proposed system introduces a hybrid multimodal approach, wherein convolutional neural networks (CNNs) are employed for extracting spatial features from screen images, and long short-term memory (LSTM) networks are used for sequential analysis of textual data derived from the same.
Another critical challenge in screen monitoring systems is user privacy. Traditional centralized machine learning models require the transfer of raw data to a central server for training, which raises serious concerns around data ownership, misuse, and security. These concerns are particularly pronounced in scenarios where screen content might contain sensitive personal or organizational information. To mitigate these issues, this project incorporates a federated learning paradigm. Federated learning allows clients to train models locally on their own devices using private data, and only share the trained model parameters—not the data itself—with a central server. This distributed learning framework significantly reduces privacy risks and aligns with contemporary standards for secure and ethical AI development.
However, even within federated learning, the exchange of local model updates can potentially leak information about the underlying data through model inversion or gradient leakage attacks. To further enhance the privacy-preserving capabilities of the system, this work integrates homomorphic encryption (HE) into the federated learning pipeline. Homomorphic encryption is a cryptographic technique that enables computation on encrypted data without the need for decryption. By encrypting local model updates before transmission, and aggregating them securely at the server using techniques such as Federated Averaging (FedAvg) over ciphertext, the system ensures that sensitive data is never exposed at any point in the training pipeline.
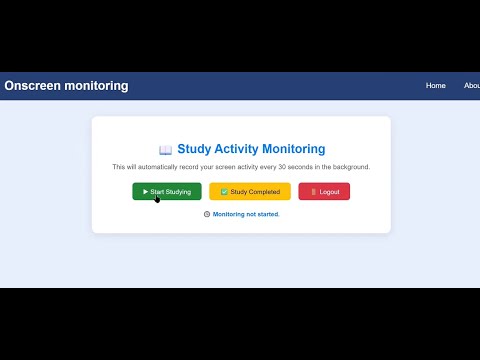
The implementation architecture consists of both client-side and server-side components. On the client side, the system captures screenshots at regular intervals, processes the images to extract embedded textual content using Tesseract OCR, and then preprocesses both the visual and textual data for model input. The hybrid model featuring CNN layers for image features and LSTM layers for text processes the combined information to learn discriminative patterns related to user screen activities. This model is trained locally on each client’s dataset, and the encrypted model weights are transmitted to the central server.
The server-side component, built using the Flask web framework, acts as the coordinator for the federated learning process. It receives encrypted model updates from multiple clients, performs secure aggregation using homomorphic operations, and then decrypts the aggregated result to update the global model. The updated global model is redistributed to all participating clients for the next round of training. This cycle repeats until convergence is achieved or a pre-defined performance threshold is met.
To ensure generalizability and scalability, the system supports an extensible number of client devices. The system architecture is modular and capable of accommodating various hardware and software environments, including edge devices, desktop platforms, and cloud-based infrastructures. A key strength of the proposed design is its emphasis on real-time screen activity classification, which is enabled through efficient preprocessing, lightweight model architectures, and periodic model updates via asynchronous federated rounds.
In conclusion, this project proposes a secure, scalable, and privacy-conscious screen activity classification system that effectively combines image and text analysis through a multimodal deep learning model, trained collaboratively across multiple clients via encrypted federated learning. The resulting system not only achieves high classification accuracy but also adheres to stringent data protection standards, making it suitable for widespread deployment in both consumer and enterprise contexts.
Block Diagram