ABSTRACT
This project introduces a machine-learning–based framework designed to classify an individual’s activity or health condition using vital physiological parameters. The system focuses on three measurable inputs—body temperature, SpO₂ level, and heart rate—and predicts the corresponding accelerometer status, which represents whether the person is in a normal or abnormal state. A Random Forest classifier serves as the core model due to its ability to manage heterogeneous data, minimize overfitting, and provide high interpretability. The dataset is cleaned, encoded, and divided into training and testing subsets to ensure balanced model learning and unbiased evaluation. Performance is assessed through accuracy and detailed classification metrics, demonstrating the reliability of the trained model. The final model and label encoder are serialized using Joblib to support deployment outside the development environment. To make the solution practically accessible, a Flask-based web interface is integrated with the trained classifier. Users can manually submit real-time physiological values and instantly obtain a predicted health status. This makes the system suitable for remote monitoring, preliminary health screening, and early anomaly detection. The project not only demonstrates a complete workflow—from data preprocessing and model training to deployment—but also highlights the potential of lightweight machine-learning systems in supporting healthcare applications. The modular architecture allows future extensions such as adding more biomarkers, incorporating wearable sensors, or migrating to cloud-based platforms for large-scale usage. Overall, the solution provides an efficient and scalable approach for health-status analysis using supervised learning and web technologies.
INTRODUCTION
Health monitoring has become a critical component of modern healthcare systems due to the growing emphasis on early detection, preventive care, and remote patient supervision. As the global population rises and the burden on healthcare infrastructure intensifies, there is a strong need for intelligent systems capable of providing timely and reliable insights into an individual’s physiological condition. Traditional healthcare models depend heavily on clinical visits, periodic checkups, or continuous human supervision, which can be inefficient or impractical for patients with chronic illnesses, elderly individuals, or people living in remote locations. Advances in sensor-based data collection, wearable technologies, and machine-learning algorithms have enabled the development of automated systems that can interpret physiological signals and produce real-time assessments. In this context, vital parameters such as body temperature, blood oxygen saturation (SpO₂), and heart rate serve as key indicators of human health status and can be used to identify irregularities, physical stress, or abnormal activity levels. The integration of these physiological markers into a machine-learning–based classification framework forms the foundation of this project. Machine learning has demonstrated exceptional potential in translating raw sensor data into meaningful health insights. Unlike rule-based systems, which rely on manually encoded thresholds or static decision logic, machine-learning models learn patterns directly from real-world datasets. This capability allows them to capture nonlinear relationships, subtle variations, and complex trends within physiological signals. Among the various algorithms available, Random Forest has emerged as a robust and highly effective model for classification tasks involving multidimensional health data. The algorithm operates by constructing an ensemble of decision trees, each trained on a random subset of features and samples, thereby improving predictive accuracy and minimizing overfitting. Its inherent ability to manage noisy data, handle correlated variables, and generate feature-importance rankings makes it suitable for clinical and near-clinical applications. In this project, Random Forest is used to analyze the relationship between vital parameters and the accelerometer-derived health label, enabling a classification output that signifies whether the health status falls within normal limits or shows signs of irregularity.
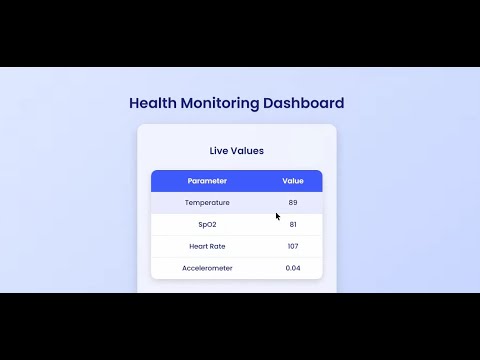
The use of accelerometer status as a target variable provides an additional layer of insight into physical behavior and overall physiological condition. Accelerometer readings are frequently used in wearable healthcare devices to track motion signatures, physical activity, and abnormal movement patterns that may correlate with health deterioration. By correlating vital signs with accelerometer-based labels, the system attempts to infer a higher-level interpretation of the user’s condition. For example, reduced SpO₂ combined with elevated heart rate may signal physiological strain or underlying health complications. Similarly, abnormal temperature readings might indicate infection or metabolic imbalance. Mapping these signals to an activity label helps create a more holistic view of an individual's well-being. Such an approach aligns with emerging trends in digital healthcare, where multi-sensor fusion is increasingly adopted to provide deeper diagnostic insights. In addition to model development and performance evaluation, a key focus of this project is the practical deployment of the trained classifier. Machine-learning models often remain confined to research environments due to deployment challenges or lack of real-time accessibility. To bridge this gap, the project integrates a lightweight Flask-based web application that allows users to interact with the model through a simple, user-friendly interface. Flask, as a micro-framework, provides a flexible and efficient platform for hosting predictive models while maintaining low resource consumption. Within the web interface, users can manually input physiological data such as temperature, SpO₂, and heart rate. The system then processes the input through the trained Random Forest classifier and instantly displays the predicted health status. This approach not only demonstrates the deployability of machine-learning models in real-world scenarios but also highlights the potential of integrating AI solutions with accessible web technologies. Furthermore, early anomaly detection facilitated by machine learning can improve response times during medical emergencies or detect subtle changes that may precede serious health issues. Systems like the one developed in this project serve as foundational components for building comprehensive, scalable health-monitoring ecosystems. In summary, this project aims to develop an intelligent classification system that leverages physiological inputs—temperature, SpO₂, and heart rate—along with Random Forest–based machine learning to classify accelerometer status. The work spans dataset preparation, model training, performance evaluation, and deployment through a Flask-based interface. The project illustrates the complete lifecycle of a machine-learning solution and demonstrates how technical components can be integrated to create practical, user-oriented health assessment tools. The system’s modularity, accessibility, and potential for expansion make it a promising prototype for future applications in remote health monitoring, wearable technology integration, and intelligent healthcare systems.
OBJECTIVES
The primary objective of this project is to design and implement an intelligent health-status classification system capable of analyzing key physiological indicators and predicting the corresponding accelerometer-based state using machine-learning techniques. The system aims to bridge the gap between raw sensor data and meaningful health insights by leveraging temperature, SpO₂, and heart-rate readings as core input features. One of the central goals is to construct a model that can accurately differentiate between normal and abnormal conditions, thereby enabling early detection of irregular patterns that may require attention. The project seeks to demonstrate how machine-learning algorithms, particularly the Random Forest classifier, can be effectively employed to manage physiological data, identify nonlinear relationships among vital parameters, and produce reliable classification outputs. By focusing on a simplified yet clinically relevant dataset, the project ensures that the solution remains practical, scalable, and adaptable for real-world health-monitoring scenarios. Another key objective is to establish a comprehensive machine-learning pipeline that includes dataset preprocessing, feature analysis, model training, testing, and validation. Data-driven health applications require clean and well-structured datasets to ensure the accuracy and dependability of predictive models. Therefore, one of the goals is to preprocess the dataset by handling missing values, converting categorical variables into numerical representations using label encoding, and organizing the dataset into training and testing subsets. These steps are intended to ensure that the model generalizes well and produces stable results when exposed to new or unseen data. A further objective is to evaluate the model using standard performance metrics such as accuracy and classification reports. These metrics help measure the predictive capability of the classifier and highlight areas for refinement. The project aims to produce a model that not only performs efficiently during training but also demonstrates robustness and consistency during real-world deployments.
Block Diagram