ABSTRACT:
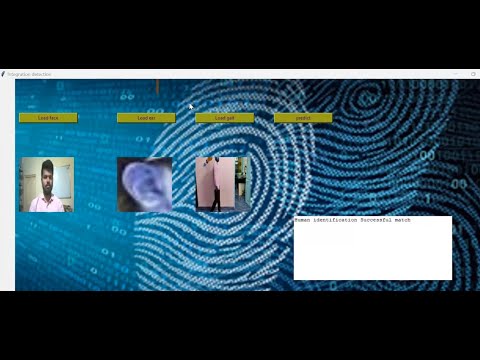
Person identification using multimodal biometric data is a robust approach that leverages multiple sources of information to achieve high accuracy. This study presents a methodology for identifying individuals using facial images, ear images, and gait patterns extracted from video frames. We capture frames from video files, preprocess the images, and train convolutional neural networks (CNNs) to recognize each modality separately. The facial images, ear images, and gait patterns are processed through their respective CNNs, which are optimized for accuracy in classification tasks. The individual outputs from these models are then combined using a fusion technique to produce a final identification result. This multimodal approach enhances the reliability of person identification by mitigating the limitations inherent in single-modality systems, ultimately providing a more comprehensive and accurate identification solution. The methodology demonstrates the potential for improving security and authentication systems by integrating multiple biometric modalities.
INTRODUCTION:
In recent years, the demand for reliable and accurate person identification systems has grown significantly across various domains, including security, access control, and forensic investigations. Traditional identification methods, such as passwords and ID cards, are increasingly vulnerable to theft, loss, and forgery. As a result, biometric systems, which utilize unique physiological and behavioral traits, have emerged as a superior alternative. Among the various biometric modalities, facial recognition, ear recognition, and gait analysis have shown considerable promise due to their distinct and stable features.
Facial recognition is widely used and studied due to the rich information present in facial features, which can be captured unobtrusively. Ear recognition, though less common, provides a unique and stable set of features that remain relatively unchanged throughout a person's life. Gait analysis, which involves the study of an individual's walking pattern, offers a dynamic biometric trait that can be captured from a distance without requiring the subject's cooperation.
Despite the advantages of each modality, relying on a single biometric trait can be limiting due to various challenges such as occlusion, changes in lighting, and variations in pose and expression. Multimodal biometric systems, which combine multiple sources of biometric data, can address these limitations by providing complementary information and improving overall identification accuracy and robustness.
This study proposes a multimodal biometric identification system that integrates facial images, ear images, and gait patterns to enhance person identification. The methodology involves capturing video frames, preprocessing the images, and training convolutional neural networks (CNNs) for each modality. By fusing the outputs of these CNNs, the system aims to achieve a more reliable and accurate identification performance compared to single-modality systems.
PROBLEM STATEMENT:
This research addresses limitations in unimodal biometric systems (face, ear, gait) due to occlusions, lighting, and variability. It proposes a multimodal system combining Convolutional Neural Networks (CNNs) for face, ear, and gait recognition. The system aims to enhance accuracy and robustness through feature fusion. It investigates preprocessing, feature extraction, and CNN model training for each modality. Evaluation against unimodal systems validates improved performance in security and identification applications. The goal is a scalable, efficient system overcoming traditional biometric challenges. This research aims to advance biometric technology for more reliable and accurate personal identification in diverse conditions.
OBJECTIVE:
The objectives of this research endeavor focus on advancing the field of biometrics through the integration and optimization of multimodal recognition systems. The primary goal is to develop a robust system that seamlessly integrates face, ear, and gait biometrics using Convolutional Neural Networks (CNNs). This integration aims to leverage the strengths of each modality to improve overall recognition accuracy and reliability in various real-world scenarios. Key objectives include investigating methods for effective feature fusion across modalities, optimizing preprocessing techniques and feature extraction algorithms tailored to each biometric type, and training CNN models specifically designed for face, ear, and gait recognition tasks. Additionally, the research aims to comprehensively evaluate the performance of the multimodal system against traditional unimodal benchmarks, focusing on scalability, efficiency, and the ability to operate effectively in challenging environments such as varying lighting conditions and occlusions. Ultimately, this research seeks to contribute to the advancement of biometric technology by addressing current limitations and enhancing the applicability of multimodal biometric systems in practical security and identification applications.
Block Diagram